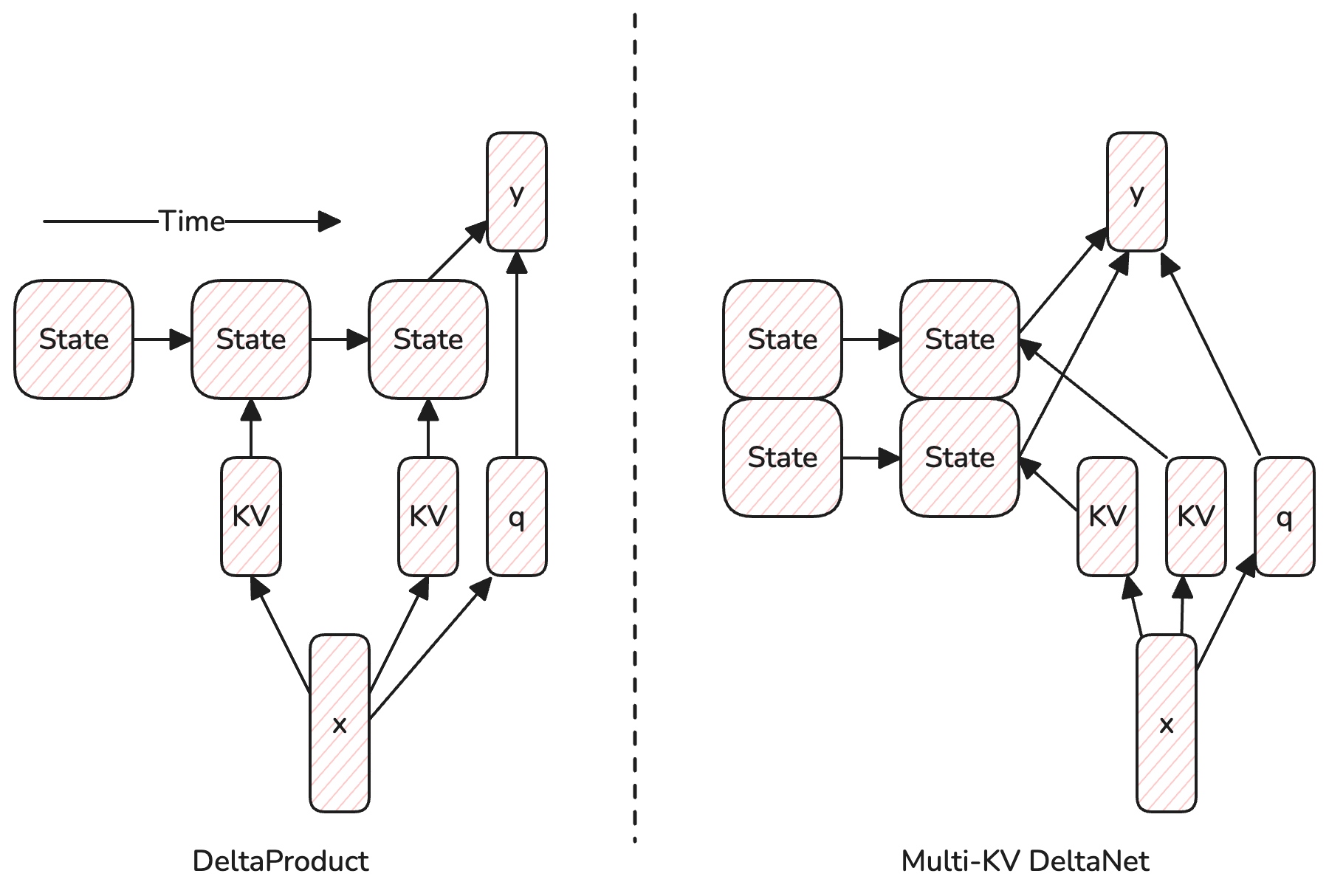
The Rise of Test-Time Training
Abstract: The main idea in test-time training (TTT) (Sun et al. 2024) is that a model with fixed parameters produces the supervision for another network that is updated during test-time (or inference-time). This article first reviews the TTT paper. Then, we discuss the problem with TTT and how LaCT addresses them, resulting in a powerful attention alternative that balances efficiency and performance. Currently, “test-time training” is an overloaded term with multiple meanings. In this article, we use the term to refer to the test-time training paradigm proposed in Sun et al. 2024, which is a framework for recurrent architectures for sequence modeling. ...