(EREN) Robust and Scalable Model Editing for Large Language Models
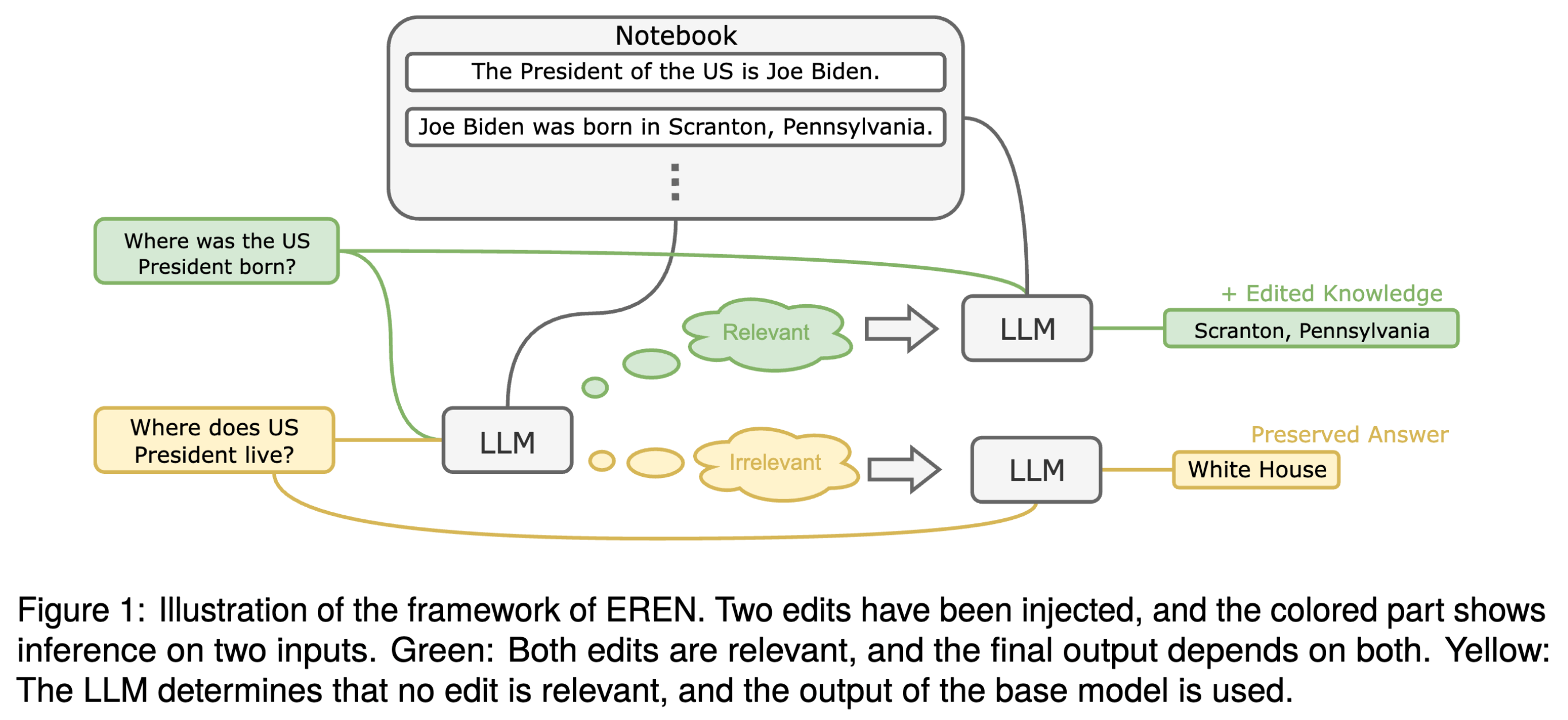
1 | 1 TL;DR : A reader is augmented with a growing notebook that caches all edits in natural texts, and the reader retrieves relevant edits and make inference based on them. This achieves SOTA in model editing in QA and fact checking.