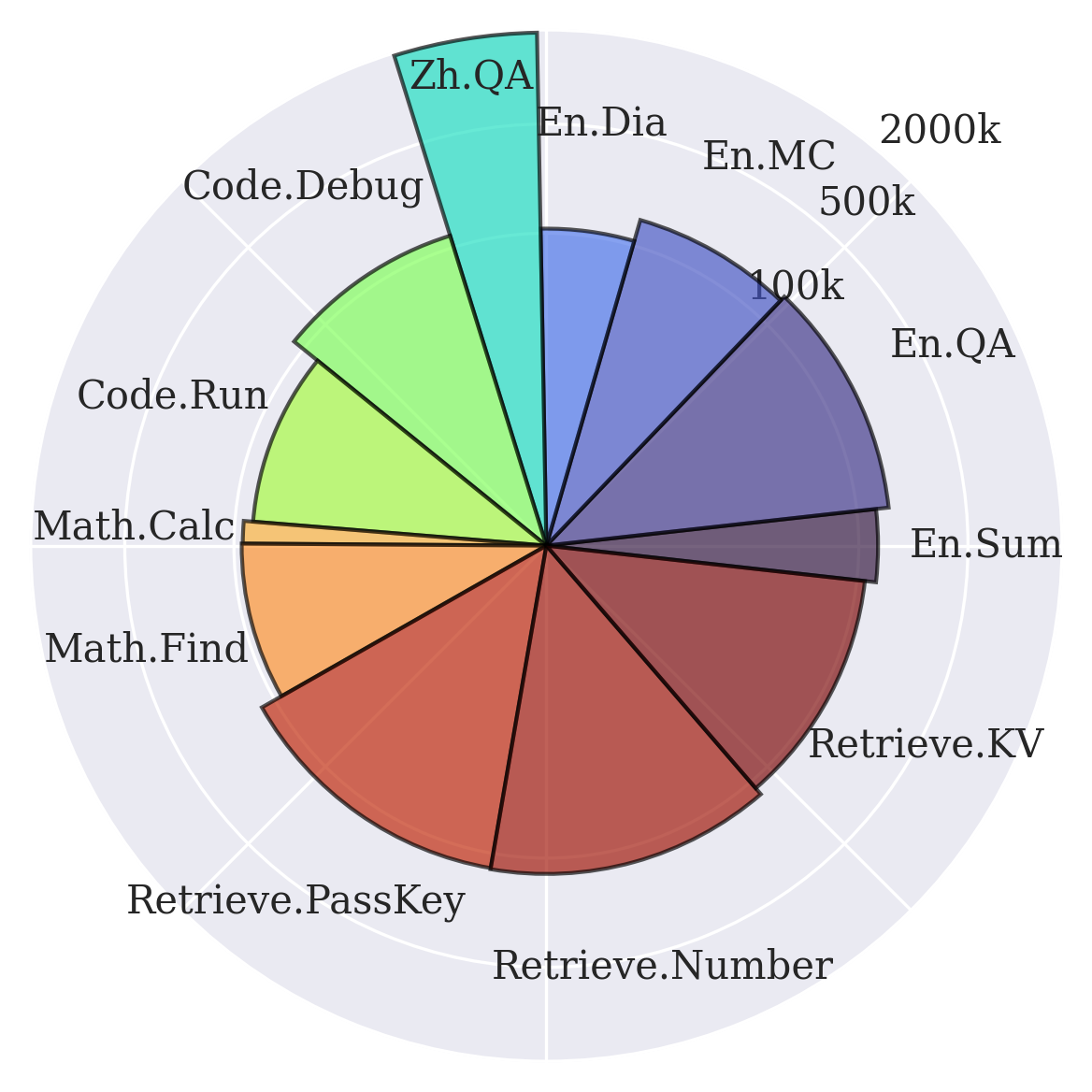
InfiniteBench: Extending Long Context Evaluation Beyond 100K Tokens
Code | Paper The first benchmark for evaluating the effectiveness of LLMs in handling more than 100k tokens! In the paper, we name it $\infty$-Bench, but I will sometimes use “InfiniteBench” in this blog post for better readability. Finally got some time to write this blog, been so busy lately! I have been in a fairly long duration of research hiatus, meanwhile the field of NLP has been revolutionized by an overwhelming number of new LLMs. Finally, I was able to arrive at some productive and meaningful work in this new era of research, as a second author. In this blog post, I will introduce this work that I have been working on recently. ...