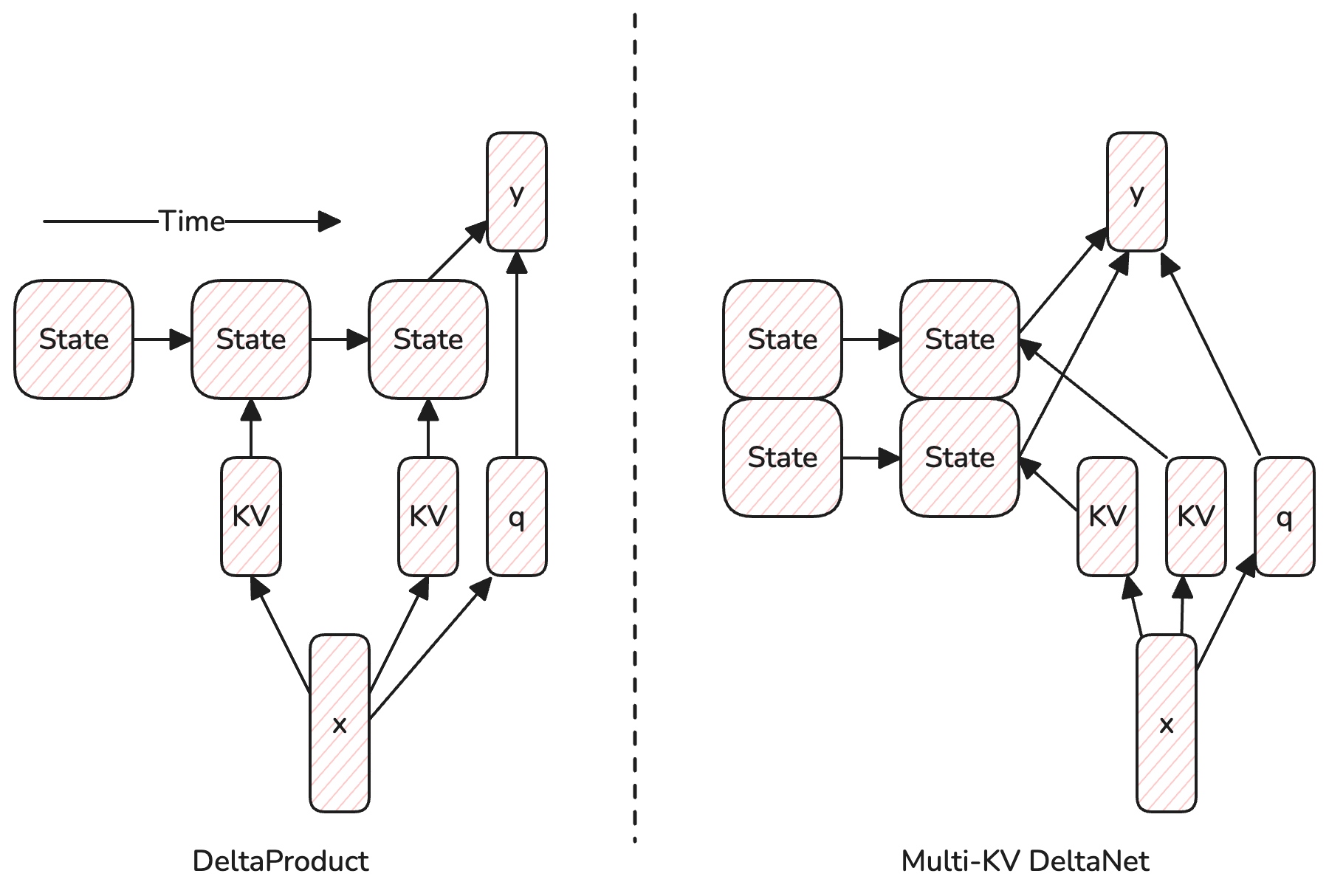
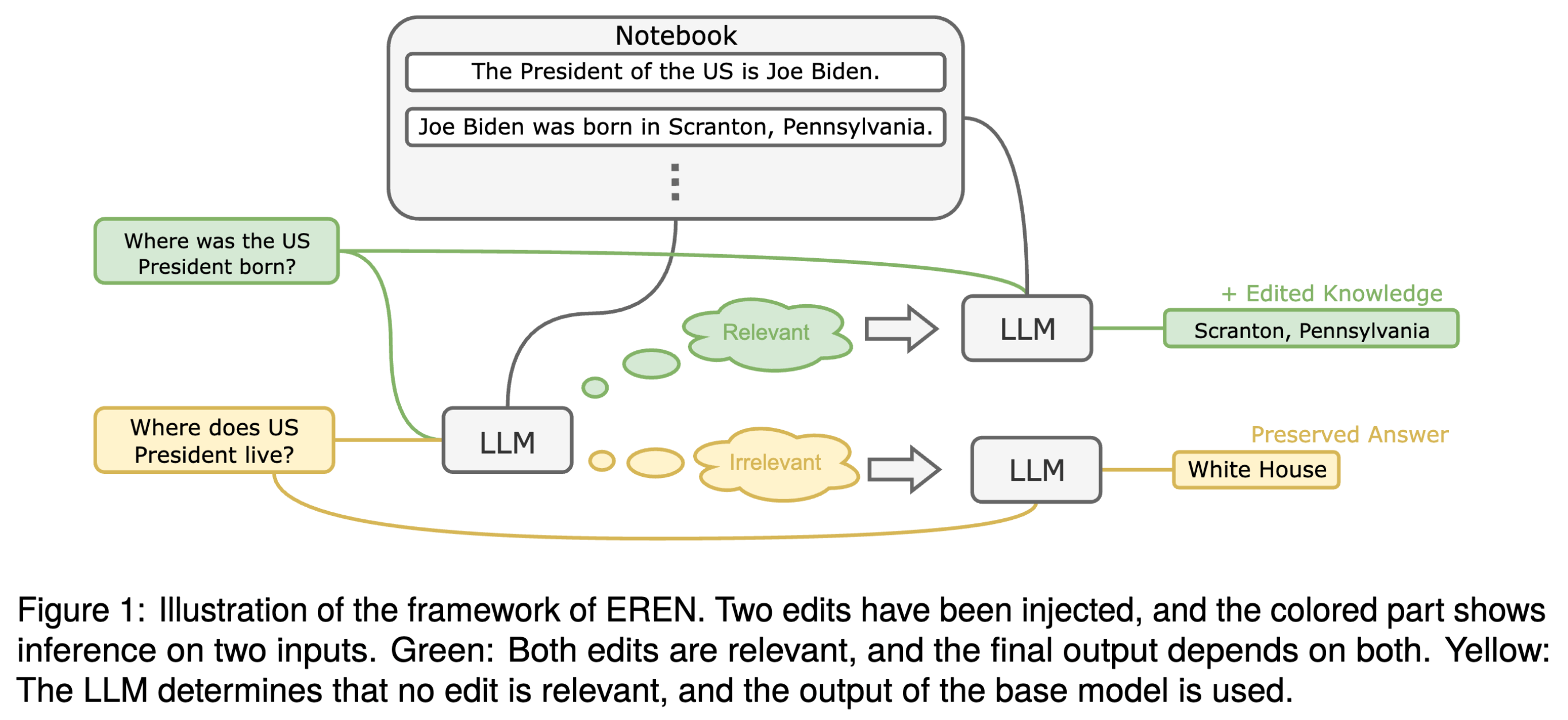
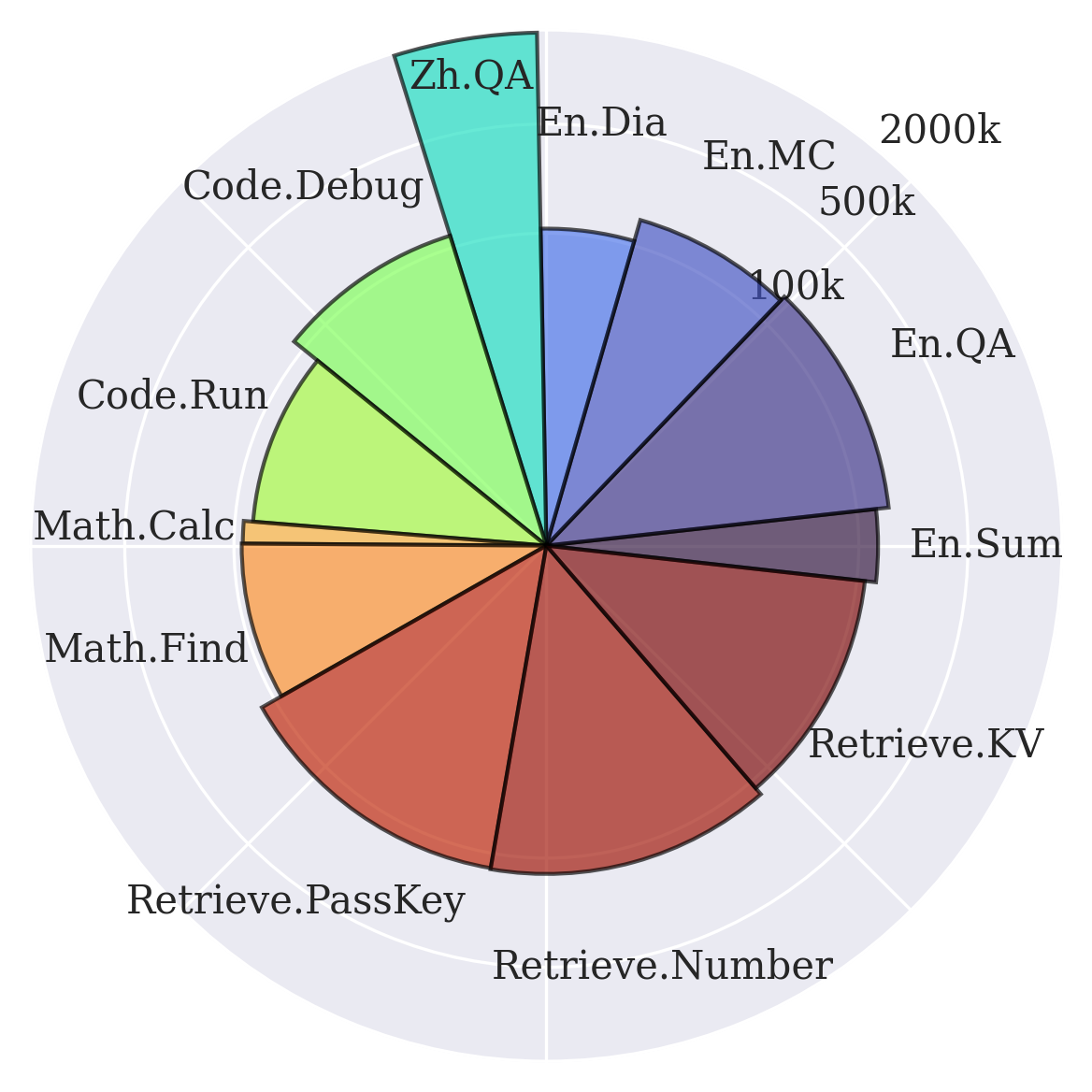
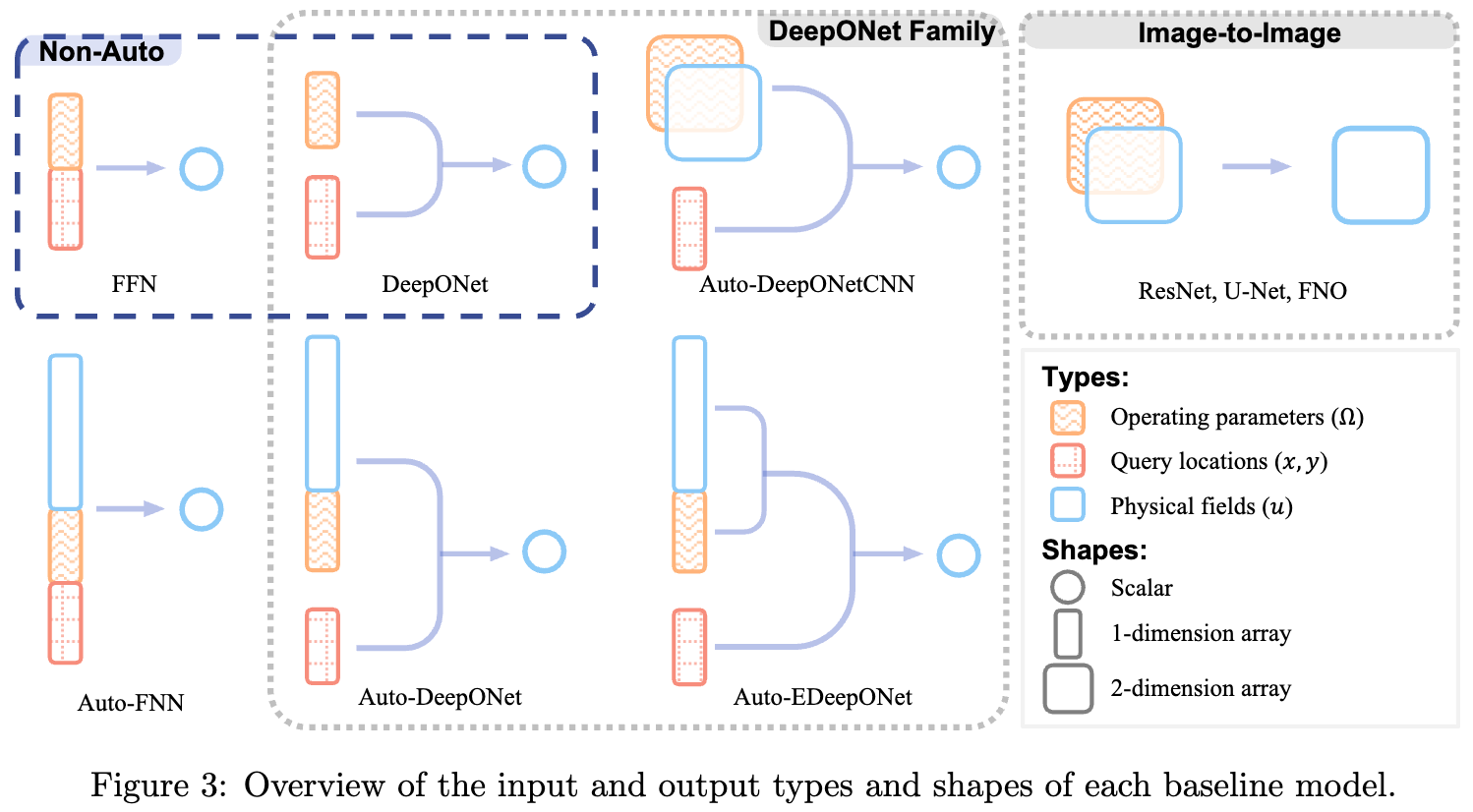
The Rise of Test-Time Training
Abstract : The main idea in test time training (TTT) ( 1) is that a model with fixed parameters produces the supervision for another network that is updated during test time (or inference time). This article first reviews the TTT paper. Then, we discuss the problem with TTT and how LaCT addresses them, resulting in ...